When evaluating an enterprise technology stack, the build vs buy ai decision used to be a simple coin toss.
Three years ago, most enterprises were building narrow prompt-response applications like basic chatbots, code copilots, or document summarizers. Your architectural choice usually came down to a straightforward question: do we call a frontier model API, or do we host an open-source model ourselves? The workflows were bounded, the operational complexity was manageable, and most failures were completely reversible.
Not anymore.
In 2026, we have officially entered the era of Agentic AI—systems that don’t just generate text, but autonomously execute multi-step workflows and take actions. The moment an AI system transitions from responding to acting, the old software evaluation rules break down.
The companies winning with enterprise technology strategy right now haven’t found a clever new answer to this dilemma. Instead, they run an exact build vs buy ai audit across every individual component of their infrastructure. They’ve started asking a much better question: At which layers of the stack should we build, and at which should we buy?
Here’s what those layers are, and what is the right decision to take at each layer.

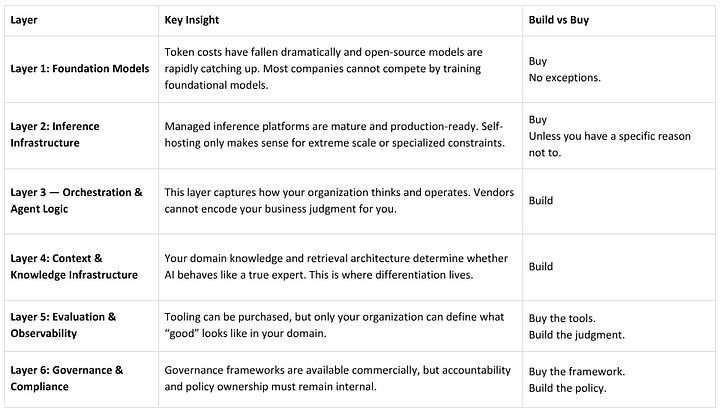
The Layer Doctrine helps you decide where in the AI stack to build or buy. But that still leaves another question:
Which AI initiatives are actually worth building in the first place?
This is where the Commodity/Conviction Grid becomes useful.
A Strategic Grid for the Build vs Buy AI Decision
The framework is simple. Plot your AI initiatives on two axes:
Axis 1: Strategic differentiation value. Is this capability core to how you win in your market? Does it touch the thing that makes your business hard to replicate? Or is it operational hygiene (necessary but not distinguishing)?
Axis 2: Proprietary data advantage. Do you have data assets that would make a custom system meaningfully better than a vendor’s generic solution? Or is your data unremarkable, similar to what any vendor has already trained on?
This creates four quadrants:
- High differentiation + High data advantage → Build.
Custom AI systems trained on, or tightly integrated with, your proprietary data, serving use cases where AI performance is a direct competitive lever. - High differentiation + Low data advantage → Hybrid.
This is more nuanced. You care about the outcome, but you don’t have data leverage. In these cases, the smartest approach is usually:
→ buy the commodity intelligence aggressively,
→ but build the surrounding system.
Make sure your proprietary value is in the layers above the model, not in your prompt engineering. - Low differentiation + High data advantage → Monetize.
You have a data asset that makes AI better — but you’re not using it for competitive advantage. Don’t build internal AI systems to exploit it for routine tasks; consider it it can be an asset to monetize externally. - Low differentiation + Low data advantage → Buy. These are capabilities that matter operationally, but they rarely create durable competitive advantage. Building here is expensive vanity. Buy the best vendor, deploy it fast, instrument the outcomes

6 step decision protocol
Given all of this, here’s how I’d approach a build vs. buy decision in 2026, working from first principles:
Step 1: Which layer are you evaluating?
The right answer for models, orchestration, retrieval, evaluation, or governance will rarely be the same.
Step 2: Map to the Commodity/Conviction Grid.
For this specific use case, what is the strategic differentiation value? What is your proprietary data advantage? This determines whether the outcome of the decision is a competitive asset or operational hygiene.
Step 3: Calculate the real TCO, including capability debt.
Build the three-year total cost of ownership model that includes: engineering time, maintenance overhead, model update costs, data quality investment, observability infrastructure, governance compliance, and the organizational cost of not developing the capability internally. Then add the capability debt risk premium — what will it cost you if you need to understand this deeply in 18 months and you’ve outsourced it?
Step 4: Assess your organizational AI maturity.
Do you have the LLMOps talent to operate what you’re proposing to build? Do you have evaluation infrastructure? Do you have governance capability? If the answer is no, you have two choices: buy to bridge the gap while building the capability in parallel, or be honest that you’re not ready to own this layer yet and buy fully with a plan to transition.
Step 5: Design for portability, regardless of the answer.
If you buy, architect the integration so that your proprietary value lives in layers your team owns, not in the vendor’s platform. When a better model emerges or pricing shifts, you should be able to swap the underlying LLM while preserving everything your team built above it.
Step 6: Decide with a sunset clause.
Build vs. buy is not a permanent decision. The market is moving too fast. Every significant AI investment should have an explicit review trigger: either a time horizon (revisit in 12 months) or a condition (revisit when vendor X reaches feature Y or when our inference costs exceed $Z/month).
The worst buy decisions I’ve seen were treated as architecture — immutable, foundational, not to be questioned. The best ones were treated as a current best answer, held lightly, under continuous evaluation.

Conclusion
Let me end with what I actually believe, stripped of hedging.
The build vs. buy question matters less than it used to because the real differentiation in AI systems is no longer in the components — it’s in the composition.
- The model is a commodity.
- The API is a commodity.
- Even the orchestration framework is becoming a commodity.
What’s not a commodity is the institutional knowledge you encode in your systems, the evaluation discipline you build to maintain quality, and the operational maturity you develop to run AI systems reliably in production.