GPU compute is the most expensive line item in modern AI development. Whether you’re training a foundation model or fine-tuning a domain-specific LLM, every idle GPU second translates directly into wasted budget. Meta recently published a detailed breakdown of how their engineering teams tackled 30–40% overhead in GPU training time — and the fixes are more accessible than you might think.
This post unpacks what Meta did, why it matters at every scale, and how these principles apply to AI teams across industries — from hyperscalers in the US to fast-growing AI startups in India, Southeast Asia, and Europe.
What is “Effective Training Time”?
Meta introduced a formal metric called Effective Training Time (ETT%), defined as the percentage of total end-to-end wall time spent actually consuming and training on new data. Everything else — initialization, compilation, checkpointing, shutdown — is overhead.
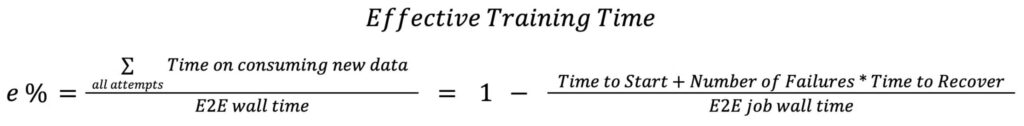
As Meta’s engineering team notes, end-to-end runtime increasingly includes overheads beyond “real training”: initialization, orchestration, checkpointing, retries, failures, and recovery.
Most teams track total training time. Very few track effective training time. That blind spot is costing real money.
At a $2–3/hour per GPU rate across a 512-GPU cluster running for weeks, a 10% improvement in utilization saves hundreds of thousands of dollars annually. For AI teams in India running cloud-based training workloads on AWS, GCP, or Azure — where GPU costs are identical globally — the same arithmetic applies.
Four fixes to reduce GPU compute costs:
Meta focused optimizations on trainer initialization, PT2 compilation, checkpoint management, and shutdown time — collectively pushing their Effective Training Time percentage above 90% for offline training by end of 2025.
Here’s a technical breakdown of each intervention:
1. Local initialization: Stop broadcasting to every GPU
During cluster setup, GPUs were using all_gather calls to broadcast metadata across every rank in the job. At Meta’s scale — thousands of GPUs — this meant minutes of synchronized waiting before a single training step began.
Instead of relying on numerous all_gather calls to build shard metadata piece by piece, each rank now builds its section of the global rank using metadata that is already locally available after the sharding plan broadcast. This change significantly improved sharding time.
The principle: Eliminate unnecessary inter-GPU communication during setup. Each GPU should do as much local work as possible before joining the collective.
This fix is available in open-source via TorchRec sharding plan improvements — no Meta-scale infrastructure required.
2. Parallelized PT2 Compilation: Don’t Wait for Real Data
PyTorch 2.0 compilation is one of the costliest pre-training steps. Previously, it couldn’t begin until the first batch of real training data was available — meaning the data pipeline and the compiler were running sequentially.
To enhance efficiency, Meta introduced new technology to use a “fast batch” to quickly get data, which allows PT2 to start compiling much earlier while the data pipeline (DPP) is still fetching the first batch of real data. This parallel execution is most beneficial for larger models, such as Foundation Models, because their data loading process is significantly more time-consuming.
In practice: compile on dummy data in parallel with real data loading. Both finish together instead of one waiting on the other.
Open-source equivalent: PyTorch 2’s torch.compile with fullgraph=True and compilation caching (MegaCache) enables similar benefits for teams not at Meta’s scale.
3. Async Checkpointing: Save State Without Freezing Training
Model checkpointing — saving the current state of weights and optimizer — used to freeze the entire training loop. At regular intervals, training stopped, the state was written to disk, and only then did training resume.
Meta moved checkpointing to an asynchronous background process. Training continues uninterrupted while a separate process handles the save operation.
Why this matters for your team: If you’re checkpointing every 30 minutes on a 48-hour training run, and each checkpoint adds even 2 minutes of frozen time, that’s nearly 2 hours of dead GPU time. Async checkpointing eliminates this entirely.
PyTorch’s torchsnapshot and distributed_checkpoint libraries support async checkpointing and are publicly available.
4. Move Model Publishing to CPUs: Stop Wasting GPUs on CPU Work
After training completes, model optimization for inference (quantization, format conversion, publishing) was running on GPUs. This is computationally inexpensive work that doesn’t benefit from GPU parallelism.
Switching to CPU machines instead of GPUs for model publishing for inference resulted in savings on GPU hours for jobs’ shutdown time.
The result: 30 minutes of GPU time recovered per job, at zero cost to model quality.
For MLOps teams: Audit your post-training pipeline. Quantization, ONNX export, and model registry uploads are all CPU-appropriate tasks. Running them on expensive GPU instances is a silent budget drain.
Compounding cost problem in AI training
These aren’t isolated edge cases. GPU inefficiency compounds across the training lifecycle:
- Larger models mean longer initialization times, more checkpoints, and heavier compilation overhead
- Longer training runs multiply every inefficiency — a 1% overhead on a 7-day run is 100+ minutes of wasted compute
- Multi-job pipelines (pre-training → fine-tuning → RLHF → evaluation) stack these inefficiencies across every stage
For AI teams in high-growth markets like India, where companies are rapidly scaling their own LLM training capabilities — from fintech models to regional language AI — these inefficiencies can make the difference between a sustainable training budget and one that quickly spirals out of control.
The same applies to AI research labs across Southeast Asia, the Middle East, and Europe that are increasingly training their own models rather than relying solely on API access.
Open-Source Tools Available Today
| Optimization | Meta’s Solution | Open-Source Equivalent |
|---|---|---|
| Local initialization | Custom TorchRec sharding | TorchRec sharding plan optimizations |
| Parallel compilation | Fast batch + PT2 overlap | torch.compile + MegaCache |
| Async checkpointing | Background save process | torchsnapshot, torch.distributed.checkpoint |
| CPU model publishing | Infra routing | MLflow, BentoML, ONNX export on CPU |
All of these are accessible to teams running standard PyTorch training pipelines on cloud infrastructure.
Building a Culture of Training Efficiency
Beyond the technical fixes, Meta’s approach signals something important: they built observability into the training pipeline itself. They defined ETT%, instrumented it fleet-wide, and used it to prioritize engineering investment.
Most AI teams don’t have this. They know training “takes a long time” but can’t pinpoint where the time goes. Building even basic observability — tracking time-to-first-batch, compilation duration, checkpoint latency — gives you the data to make targeted improvements.
This is especially relevant for:
- Enterprise AI teams building internal LLMs for automation, knowledge management, or customer service
- AI startups with limited GPU budgets who need to maximize utilization per dollar
- Research institutions running academic training jobs on shared compute clusters
Takeaway for AI Leaders
GPU costs are not going down. As model sizes continue to grow and training runs get longer, infrastructure efficiency becomes a core competency — not an afterthought.
Meta’s work demonstrates that a disciplined focus on measuring, then systematically reducing overhead can recover 30–40% of training time without changing model architecture or training objectives. That’s a free performance multiplier hiding in plain sight.
The teams that build this discipline now — regardless of their current scale — will have a structural cost advantage as AI workloads intensify over the next three to five years.
How InteliGenAI can help?
At InteliGenAI, we work with enterprises and AI-native teams to design and deploy highly efficient custom AI solutions.
Whether you are configuring your first fine-tuning pipeline or managing complex enterprise deployments, our technical capabilities include:
-
Supervised Fine-Tuning (SFT) & RAG Deployments: Structuring highly efficient retrieval-augmented generation and fine-tuning workflows that maximize data throughput without burning unnecessary compute.
-
Agentic AI Architectures: Designing sophisticated, autonomous AI workflows tailored for complex operational environments across the healthcare, insurance, and enterprise sectors.
-
Infrastructure Cost Governance: Diagnosing and replacing highly inefficient legacy integrations. We specialize in engineering leaner alternatives—such as architecting custom object detection models to replace standard off-the-shelf APIs, effectively reducing processing costs by up to 90%.
If your current AI architecture is burning capital on operational overhead or inefficient integrations, the solution is better engineering.
Schedule a discussion with our team to see how we help organizations build leaner, faster, and smarter AI systems.
For the full technical deep-dive, read the original PyTorch engineering blog: Optimizing Effective Training Time for Meta’s Internal Recommendation/Ranking Workloads