Overview
Zero-shot (open-vocabulary) object detection lets models find and localize objects they were not explicitly trained on — using language prompts instead of thousands of class-specific annotations. This changes how enterprises approach vision projects: faster prototyping, less labeling, and new opportunities for real-time automation.
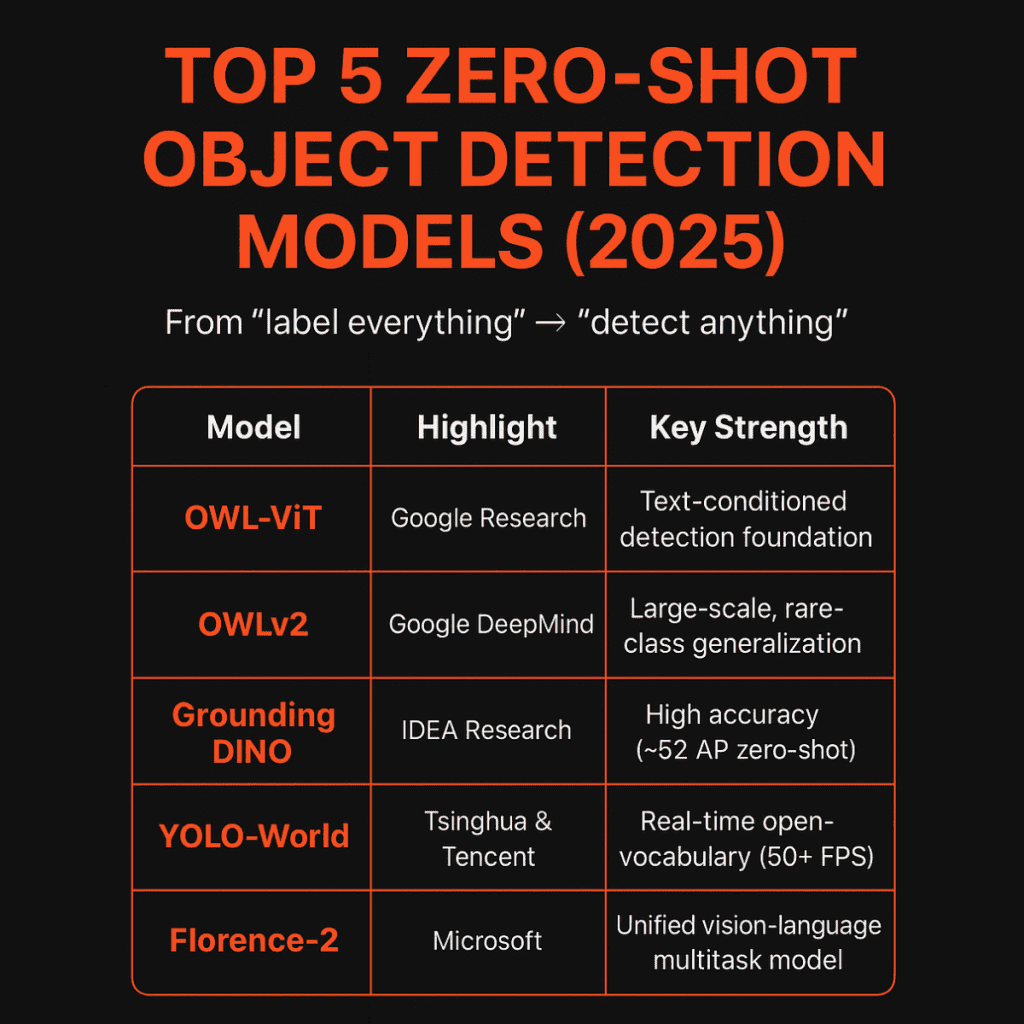
Top 5 zero-shot object detection models:
1. OWL-ViT
What it is: A foundational open-vocabulary detector that adapts vision-language backbones for localization — text-conditioned queries to find unseen objects.
Strengths:
- Highly flexible
- Great for rapid prototyping and experiments where classes change often.
Limitations:
- Early iterations may trade off inference speed or require tuning for edge production.
Best for:
- POCs
- Catalog monitoring
- Exploratory projects.
2. OWLv2
What it is: A scaled version of OWL-ViT designed for web-scale training and rare-class generalization.
Strengths:
- Improved rare-class recall and generalization
- Works well when you expect many unseen classes or long-tail categories.
Limitations:
- Higher compute requirements during training and careful prompt engineering for best results.
Best for:
- Enterprises with diverse catalogs or use cases requiring strong generalization across many categories.
3. Grounding DINO
What it is: Transformer-based open-set detector with grounded pre-training that specializes in precise localization from text prompts.
Strengths:
- Very high accuracy — notable zero-shot metrics on COCO transfer
- Suitable for high-value detection tasks.
Limitations:
- Transformer compute and latency may be higher for real-time or edge scenarios.
Best for:
- Mission-critical inspection, security, and high-precision industrial tasks.
4. YOLO-World
What it is: Combines YOLO’s efficiency with open-vocabulary capability via a RepVL-PAN fusion network and region-text contrastive learning.
Strengths:
- Real-time inference suitable for video/edge deployments
- Good balance of speed and generalization.
Limitations:
- May trade a small amount of peak accuracy for large gains in speed.
Best for:
- Live video processing
- Robotics
- Latency-sensitive application.
5. Florence-2
What it is: Microsoft’s unified vision-language foundation model — multi-task: detection, segmentation, grounding, captioning.
Strengths:
- Compact variants with strong multi-task performance
- Simplifies operational overhead when you need one model for many tasks.
Limitations:
- As a generalist, it might not exceed specialist detectors on ultra-narrow tasks without fine-tuning.
Best for:
- Organisations seeking simplified model ops across multiple vision tasks.
Quick comparative table
| Model | Strength | Deployment fit |
|---|---|---|
| OWL-ViT | Flexible text-conditioned detection | Prototype / cloud |
| OWLv2 | Rare-class generalization (web-scale) | Cloud / high-compute |
| Grounding DINO | High localization accuracy | Precision tasks (cloud/edge with tuning) |
| YOLO-World | Real-time open-vocab inference | Edge / video / robotics |
| Florence-2 | Unified multi-task model | Multi-task enterprise ops |
Decision framework:
Use this simple decision checklist before selecting a model:
- Speed vs accuracy: If latency is critical, consider YOLO-World. If precision is non-negotiable, Grounding DINO is a strong candidate.
- Class volatility: Frequently changing classes → OWL-ViT or OWLv2 for stronger generalization.
- Compute & budget: Edge deployments need lighter models or optimized inference (YOLO variants, or quantized Florence-2).
- Domain shift: Always validate with domain-specific examples and plan for targeted fine-tuning where necessary.
Enterprise implications & recommended pilot
Key takeaways for CXOs and product leaders:
- Zero-shot reduces the labeling bottleneck — convert weeks of annotation into hours of experimentation.
- Real-time zero-shot detection is production feasible — bring vision to live video or robotics pipelines.
- Unified models reduce operational complexity when you require detection, segmentation and captioning together.
Conclusion
Zero-shot object detection is a practical and high-impact evolution in computer vision. Whether your priority is speed (YOLO-World), accuracy (Grounding DINO), scale (OWLv2) or unified capabilities (Florence-2), there’s now a model strategy that fits enterprise constraints.
If you’re evaluating vision projects for 2026 across retail, manufacturing, or logistics in India & APAC, contact us.
Is zero-shot detection better than fine-tuned models?
Not necessarily. Fine-tuned models generally achieve higher accuracy within specific domains because they are trained on labeled examples of known classes.
Zero-shot models, however, excel in open-world scenarios where new or unseen object categories appear frequently. They rely on semantic reasoning rather than memorization, making them more flexible but sometimes less precise.
Reference:
When should you use zero-shot object detection?
Use it when your system encounters unlabeled or rapidly changing object classes, or when manual annotation is costly.
It’s ideal for:
Retail: detecting new product SKUs or packaging updates
Manufacturing: identifying unknown defects
Security: recognizing unseen threats or intruders
Healthcare: analyzing anomalies in medical imagery
📘 Reference:
What is the main advantage of zero-shot object detection?
Its primary advantage is generalization to unseen classes.
Zero-shot systems use vision–language alignment — mapping visual inputs and textual descriptions to a shared embedding space.
This allows detection based on semantic similarity, not explicit examples, enabling enterprises to deploy detection models that evolve without retraining.
Reference:
How does zero-shot object detection work?
Zero-shot models rely on joint embedding learning between images and text.
They typically use transformer-based architectures where visual tokens and text tokens interact through cross-attention.
At inference, the model compares detected image regions with natural-language prompts (e.g., “detect all types of machinery”) to identify relevant objects, even if they were not seen during training.
What are the limitations of zero-shot object detection?
Lower precision for fine-grained or domain-specific tasks compared to fine-tuned models.
Dependence on textual quality — poor or vague labels reduce accuracy.
Computational intensity, since large-scale vision–language models require high inference power.
Bias inheritance, as pretrained data often contains social or visual biases.